


Reactive is a buzzword thrown around a lot, but what is it really? At first glance, reactive doesn't seem to be anything special. Asynchronous stream processing seems nice, but is that all? Fortunately, the answer is no! Reactive also includes nonblocking IO, which makes resource utilization better. If you have never heard any of these terms before, it may just seem like a word-soup. Don't worry! We will explain the terms below, so you can understand the big whoop with reactive. Getting an overview of the concepts will be the main goal here, but I will provide links for further reading. Some oversimplification may happen, but I hope that it will help you understand concepts without being boggled in buzzwords and lots of pre-requisite knowledge.
What is Reactive? - The original definition
If we visit the ReactiveX website, we see the following definition: "ReactiveX is a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming"
Breaking down this original definition can be something like the following:
- Observer pattern: We are observing a stream of data. The observer function (the function we give) is called for each element.
- Iterable: We are iterating through streams of data element by element. (haven't seen any deeper meaning than this)
- Functional programming: We are using higher order functions (i.e, functions taking functions as parameters, or functions returning new functions). People often think of map, filter, reduce etc. here. For functions not interacting with external sources (IO like databases or messages), we prefer them to be purely functional (i.e, return the same result each time given the same input). Not always possible, but functions should at least NOT depend on global state.
This definition is quite hard to grasp at first glance. Your first thought might be "Say whaaaat?". First, let us create a better, more clear definition (stolen from a RedHat article that also contains code examples): "Reactive programming is working with asynchronous streams". That makes it a little more clear what the above says, right?
What is Reactive? - A more descriptive definition
The original definition makes us think of streams like in Java, and the higher order functions it entails. While this is a great beginning, and a great way to understand the way we code, I don't think it makes it clear what the big whoop is about.
To complement the previous definition, a Reactive application is:
- Event-driven: You code in a different style. Instead of the imperative style (often blocking, i.e, taking up resources on the thread for longer periods of time) we are used to, we write shorter code on the form "on event, do code". This can also be lambdas in a map transforming some data once received. This is off course an oversimplification, but the main point is acting on events whether they be data received, failures and so on.
- Nonblocking IO: We will go more into this in the next heading. Let's for now take an example to keep you interested; Imagine doing a HTTP request to an external system. A blocking call will block the thread and just wait, while a non blocking call will do the call in the background (OS level implementations) and send an event back to your code once done (often done automatically by the library and/or framework you are using). This might seem like magic, but this event queue has been a part of several operating systems for a long time. We will go deeper into this in the next section.
Reactive applications often don't exist in isolation, we want to make reactive systems (i.e, reactive applications working in tandem). You can quickly see that this becomes a distributed system (duh!). A lot can be said about these systems, but an important aspect is that the integrations shouldn't block the execution. This often lead to an event driven architecture. A system sends out an event, continues its work, the consumer consumes it, and other than that the systems live almost by themselves. No system is waiting for another to finish a request (unless waiting for an external party, where we would often use nonblocking clients like described in the next section). At the corner of our system (to external systems), HTTP can be used, but internally we often use events like those in Apache Kafka or MQ (message queue) systems like ActiveMQ.
Nonblocking IO
Nonblocking IO has been a term that has gone around like a buzzword on the internet in the last years, and few really know what it means. You might have heard about it for JavaScript runtimes like NodeJS, but do you really feel you have a grasp on the advantages of such an approach? In NodeJS you often see that you give a callback to IO functions (reading files, databases etc.), which is executed once the IO action is done. That is the start of understanding nonblocking IO. The thread is not blocked until the IO action is done, but can do other things.
Nonblocking IO is, oversimplified, just an event loop running in a single thread like this (we often call this thread the IO thread as it takes the IO requests from HTTP, messages etc.):
while(true) {
val event = getNextEvent()
processEvent(event)
}
(this can off course happen in several threads, which is something Quarkus for Java and Kotlin does)
The getNextEvent function can be blocking and wait for an event to exist, no need to process anything if no events are present. What makes this so good? If you write short non blocking code, you can use fewer threads to do more things. No more idle threads just waiting for something to finish! Remember that your event handlers have to not block the thread for long periods of time! If you block the thread, other requests won't be processed until you are done (very important for something like a web server).
One famous example of this is non blocking sockets (using select) in C, which is essentially the above. When a socket connects, we don't do much, just see that a connect event happens. When a socket is ready to send or receive data, we do that based upon the event type. No waiting for the socket to do all its work before the thread can do something else.
How is this possible? Now instead of your own code, the magic happens in your OS. Your OS has an event queue, taking in requests, and notifying the requester once their task is done. That way the thread is not just waiting for something to happen, but can be used for other things. This functionality has been part of Linux and other operating systems for a while now, and can be used by using the relevant system calls. This is something your IO driver (e.g, database) or similar have to take advantage of it they want the operations to be nonblocking.
Let's use database access as an example, because that is something you will probably do anyway. In a blocking client, your thread utilization will look something like this:
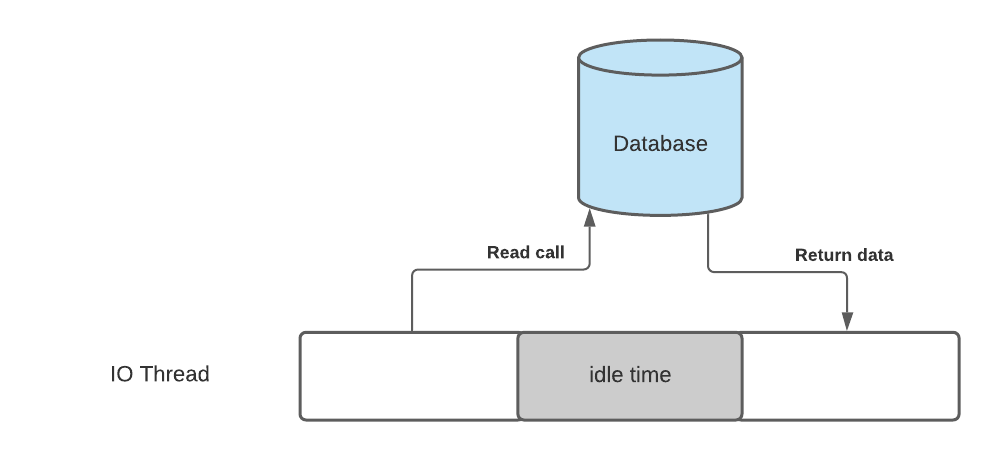
As you can see, the thread just waits for the database to return the results before it can continue. Now you might wonder what a nonblocking client looks like?
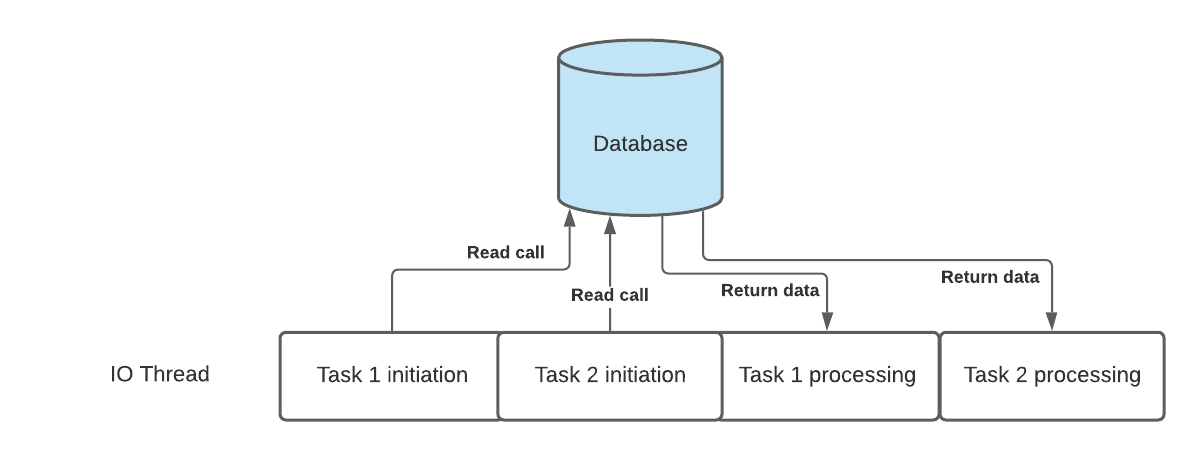
(In many instances we don't return the data in a big bang fashion to your program. We can return chunks of data one by one, so we don't get a big block of code processing a lot of data at a time!)
As we can see, the thread is used for other things while we wait for the data to be returned. This is all because of the event queue in your OS. Once the database call is done, it will send an event, and a callback function will be executed. The order of the tasks being processed will off course depend on the time the read call take. Task 2 might have a very short effective SQL, and Task 1 might have a more time consuming one. Then the order will probably be different. The main point above is to maximally use the threads.
Many databases these days have reactive clients, including PostgreSQL, Oracle, MongoDB, Redis, Neo4J etc. (so for all of your relational database, document database and graph database needs!)
Remember that spawning threads have overhead. It will create a (very) tiny bit of waiting time needing to happen to create the thread, and synchronizing the result back to the thread initiating the worker thread. These synchronizations have some very tiny performance penalties. Probably not big for your average application, but it is something you should have in the back of your head. Can your code be rewritten to a more reactive way of thinking (i.e, nonblocking) instead?
Why Reactive is loved in cloud environments (AWS, Azure, GCP etc.)
Like we mentioned with nonblocking IO above, reactive code will use less resources than standard imperative code if done correctly. Less resources will equate to a lower bill. All companies, whether you are a startup or enterprise (or even just doing your own spare time project) would like to use the resources you are paying for to the max. If you can handle more request in a cheaper manner, then why not? Combined with something like serverless, you can get minimal resource usage even for many requests. Wait, what the actual f**k is serverless? Another buzzword? Serverless is quickly summarized just instances that activates to service the calls being done (i.e, not running all the time, only when needed), running only the instances needed, and doing small amounts of work. So together with reactive, it uses just the minimal amount of resources on your cloud provider. Examples include Azure Functions and AWS Lambda. Serverless might be a weird word, because we still have servers, but our applications only run on them when needed. When not used, our cloud provider uses the machines for other peoples serverless functions (at least to my understanding, would be stupid to just have them idle ;) )
Now you might have an impression that Reactive is only great for penny-pinching serverless functions, but that is not the case. If you have a cluster of machines (e.g, Kubernetes), you can put way more applications on a single machine if each application uses less resources.
In conclusion and further reading
Hopefully you have now gotten the main points of what Reactive programming is about. This article only scratched the surface, and there are off course more research you could do. A great start would be looking at some of the articles linked above, or looking at some libraries and how coding with them works. Examples include RxJs, RxJava, and Quarkus (JVM framework, and way more than just Reactive). If you thought event driven architectures using something like Apache Kafka sounded interesting, that can easily be done in Quarkus using Reactive principles (or done with other tools if you just want to research event driven architectures!). Project Loom can be interesting to read about as well, as its virtual threads might improve the efficiency of mixing blocking and nonblocking code in Reactive code bases in the future (or maybe kill Reactive as some people seem to think, like Brian Goetz). Maybe you instead want to know how Reactive libraries and frameworks are coded? Then you can research the patterns often used like the Reactor pattern, or Proactor pattern (used by Quarkus).
If you program in Java or Kotlin, and would like to learn more about Reactive with Quarkus, I can recommend the Reactive Systems in Java: Resilient, Event-Driven Architecture with Quarkus (Amazon affiliate link, so I earn commissions on qualified purchases).
If none of the stuff above seems like the next step, I hope I at least have given you the language you need to find it. Remember that language is power, and knowing the terms above will definitely help you do more effective searches in the Reactive and event driven spaces.

